




S3 is a general object storage service built ontop of Amazon’s cloud infrastructure. Learn about the Core S3 Concepts that you need to know about it in this article.
S3 is one of the most popular services on AWS. Launched in 2006, the service has since added a ton of new and useful features, but many of the core concepts have stayed the same.
In this blog post, I want to introduce you to the Core Concepts of Amazon S3. We’re going to learn what S3 is, some of its major concepts, useful features, pricing, use case examples, and much more.
So let’s get started…
What is Amazon S3?
S3 stands for Simple Storage Service and is an general object storage service built by AWS. It takes advantage of the vast infrastructure AWS all over the world.
I like to think of S3 as something similar to Dropbox or Google Drive in the sense that you can use it to store any file type (within some reasonable size limits). Although similar to these other products, its more oriented towards software oriented projects, but really, there’s nothing stopping you from using it to archive your personal photo library if you wish. After all, this is AWS we’re talking about here!
In terms of content that you can store on S3, you can store big files, small files, media content, source code, spreadsheets, emails, json documents, and basically anything that you can think of. Keep in mind though for a single object, there is a maximum size limit of 5 TB. This size limit probably won’t affect 99.9999% of you, but its important to know what the constraints are.
Below, I run you through some of the main performance dimensions you need to know about if using S3.
Horizontally Scalable
Performance is another reason many users flock to S3 as an object storage solution, and this is really where the advantage is over more conventional cloud storage products such as Google Drive and Dropbox.
S3 is an extremely scalable solution. You can think of it like an all you can eat buffet – there is no limit to the amount of content you can upload to S3. In distributed system world, we call S3 a horizontally scalable solution. Note that horizontally scaled systems can continue to provide predictable performance even when size grows tremendously. S3 shines in this regard.
The nice thing about S3 is that it can support applications that need to PUT or GET objects at very high throughputs, and still experience very very low latencies. For example, I once built an application that needed to read S3 objects out of a bucket at over 50 read calls PER SECOND. Size volumes varied from around 50KB to 100KB, but latencies were always low and predictable (often lower than 100ms).
In the performance category, S3 has defined a whole bunch of best practices when it comes to using S3 in highly concurrent scenarios. This includes strategies such as using multiple connections, using appropriate retry strategies, and many more tips. The link above calls out many of the suggestions by AWS – I highly suggest you give it a read.
Consistently Available
One of the really nice things about relying on cloud storage by AWS is that any service built on it gets to take advantage of the highly distributed nature of cloud computing. Service creators are able to spread out their work across different logical units (data centers, regions) to ensure that the product / service they are offering is consistently accessible. Also, AWS has dedicated networking backchannels between its data centers that allows for it to quickly start serving traffic from another data center in the scenario where one is having problems.
S3 is a rockstar when it comes to availability. Since it piggy backs ontop of AWS cloud infrastructure, its able to offer very reliable availability guarantees. Do note that the actual availability guarantee (usually defined in % format like 99%) is dependent on the different Storage Tiers that you apply to your data (more on this later).
The standard tier which is default offers 99.99% availability guarantees. There are other tiers with slightly lower guarantees (99.5% is the lowest), but this only applies to certain data storage tiers that have lower cost. If you care about your data being always accessible and don’t mind paying a premium for it, then the Standard Tier will do just fine. If you’re looking to save on cost, you can consider some of the lower availability tiers. We’ll discuss in depth the different storage tiers in an upcoming section to help you understand more of when to use what.
Another nice thing to know about is that Amazon S3 has an SLA in terms of availability, and if Amazon ever fails to meet its SLA, they will offer service credits based on the downtime percentage to your nice bill. This is a commitment to availability on AWS side. There’s a screenshot below of the uptime percentage that AWS guarantees and the credits that get applied if AWS fails to meet them.

Do keep in mind though that outages in S3 are extremely rare, so you may never need to worry about this.
Durability
In cloud computing, durability refers to how healthy or resilient your is when it comes to data loss. Since data in an S3 bucket for example is stored on the cloud, we need a way to measure how likely it is for your data to become lost. In S3’s case, its durability is advertised as 99.99999999999% (11 9’s). Without having to say it, the chances of you losing your data are not impossible, just insanely improbable.
So how does S3 achieve this incredible durability? The process involves making multiple copies of the data you upload, and separating them onto multiple different physical devices across a minimum of three availability zones.
Additionally, S3 also offers a “versioning” feature such that each time you update a version of your object, the previous version is persisted alongside it. This won’t make ‘duplicate objects’ in your bucket per se – it’ll just allow you to revert back to any other previous version with a couple clicks. Versioning does come at an extra cost, but is useful for those of you looking to go the extra mile when it comes to durability.
Integrations with Other AWS Services
This is by far my favourite feature of using S3 – its native integration into other AWS services. S3 in itself is pretty un-interesting – cloud storage…. cool?
However, what makes S3 so powerful is the fact that you can combine some of its features with other AWS services to achieve some very interesting functions. For example, you can take advantage of the S3 events feature and integrate it with a Lambda function. With this setup, you can trigger a lambda function every time a S3 object is uploaded. This can be useful for data processing, file upload notifications, and many more interesting use cases.
Additionally, you can use it to host websites by integrating your website asset files (HTML, CSS, Javascript) with Route53. You can further optimize this setup by adding caching by leveraging AWS CloudFront to serve your content from S3 using edge nodes (data centers geographically distributed throughout the world).
These are just a couple examples, but there’s many other interrogations with AWS services worth noting. We’ll go over a couple of the more popular ones later in this post.
In the next section, we’ll start to get into the details of Amazon S3’s core concepts: buckets and objects.
Core Concepts
Buckets
Buckets are the highest order concept in Amazon S3. A bucket is really just a container for items that you would like to store within a certain namespace.
When you create a bucket, you give it a name. Its important to note here that bucket names must be globally unique across ALL of AWS. So there can’t be two buckets called test, or two called production, even if they are owned by someone on a different AWS account.
In terms of what buckets represent, I like to think of buckets as a general purpose file system. The bucket itself is the top level folder and within it you can have subfolders, files, subfolders within subfolders, so on and so forth. Basically, the same as a folder on Mac / Linux.
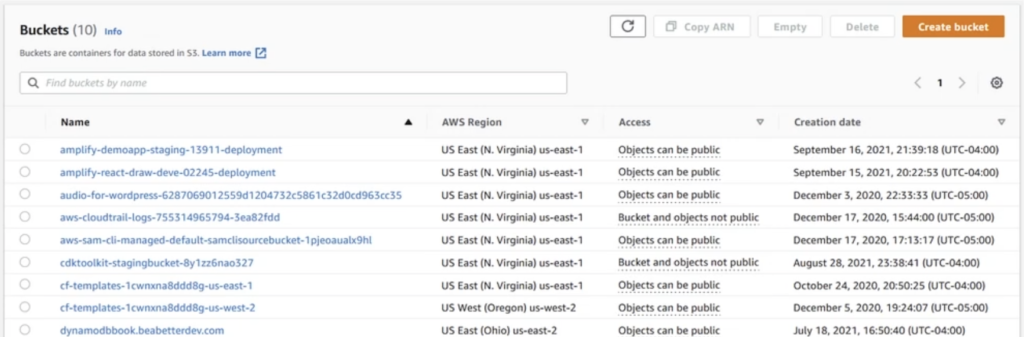
In terms of the visualizing buckets, here’s what a view of what they look like from the AWS console. Note that bucket names cannot contain special characters, must be globally unique, and need to be assigned to a corresponding AWS region upon creation.
Now we know about the basic file structure of S3. Lets move on to the content we’re storing inside them, more commonly referred to as S3 Objects.
Objects
Objects are the content that you’ll be storing inside of your buckets. They are the files, or collection of files that you upload to S3. This can range from media files, source code, zip files, and the list goes on.
Its important to remember that 5 TB size limit here – objects uploaded cannot exceed this limit.
Larger objects may have problems getting uploaded into the AWS Cloud – this can be due to spotty networking, flaky wifi networks, and many more reasons. For those of you with rather large files, you can break your files up into smaller ‘chunks’ using S3’s multi-part upload feature. This allows you to take advantage of parallel threading to upload your objects quicker and more reliably into the cloud.
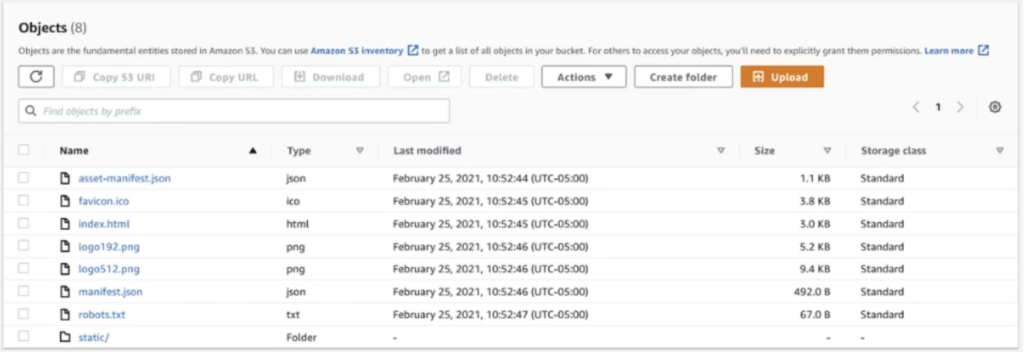
Below, we can see a list of Objects stored within an S3 Bucket. Notice we can assess object file types, modification dates, size, and storage class (more on this later). Also notice that the last record in this list is a sub-folder. These subfolders may contain objects or other sub folders. Its up to the user to decide their bucket/subfolder structure.
In terms of accessing objects, there’s a couple different ways that you can retrieve your uploaded content from s3. The first method is using a URL following the schema below.
http://s3.amazonaws.com/BUCKET_NAME/OBJECT_NAME
You’ll notice this is a HTTP link – this means that those who have the link will be able to read your object. Do note that this will not work by default – bucket owners need to explicitly specify that content within their bucket CAN be public, and whether certain objects or folders/subfolders ARE public. Its a two-step process that helps you shoot yourself in the foot by accidentally exposing your bucket to the public internet.
The second (and more popular) way to access your bucket’s content is programmatically. The code itself is pretty trivial. In the below example, I’m using Python and leveraging Boto3 library’s get_object method to retrieve my object.

Content retrieved can be deserialized as a bytestream into a system known object format where it can be manipulated based on your needs. When downloading from S3, there are different availability guarantees depending on which storage class you’re using. In the next section, we’ll talk about these storage classes and how they can drastically impact the price of using S3.
S3 Storage Classes
When S3 was originally created, there was never a concept of Storage Classes – there was only one classification you could use and only one pricing point. Storage Classes are a relatively new concept introduced post release.
Over time, S3 began being used from a variety of different use cases – and the list keeps on growing. This includes applications leveraging S3 for real time applications, data processing, data archiving, event based architectures, and many more examples.
It turned out that one size doesn’t fit all. These different use cases have different different requirements in terms of things like latency and availability. Storage classes address this problem by allowing you to classify objects within buckets into different storage classes that have different performance characteristics, and also different pricing models.
Firstly, the thing to remember is that S3 allow you to drastically reduce costs, but it comes with certain sacrifices. The biggest ones are in terms of access time (latency) to your objects, availability (how often your data is available from the S3 service) and durability (how ‘redundant’ or ‘secure’ your data is on the cloud).
A list of storage classes and a brief explanation is outlined below
- Standard Tier – The default and most commonly used tier. Great for ‘read after write’ scenarios requiring low latency, high durability and availability guarantees.
- Intelligent Tier – A tier that attempts to shuffle around your data into different tiers based on access patterns. Shuffling is done automatically and unbeknowns to the customer.
- Standard IA – Infrequent access tier. This is more suitable for older data that doesn’t need to be access often, but when it does, you need low and predictable performance.
- One Zone IA – The same as Standard IA, except your data is only persisted in one availability zone instead of a minimum of 3. Has the lowest durability guarantees at 99.5% and comes with lower cost points.
- Glacier – Suitable for archive data that needs occasional access. SLA for object retrieval ranges from a few minutes to a few hours. Low cost point.
- Deep Glacier – Best for long lasting archival data (i.e. for compliance, regulation, or policy purposes). Object retrieval within 12 hours of request time. Lowest cost point.
- Outposts – On premise S3. Essentially emulates Amazon S3 service within on-prem devices and makes the files available from local machines.
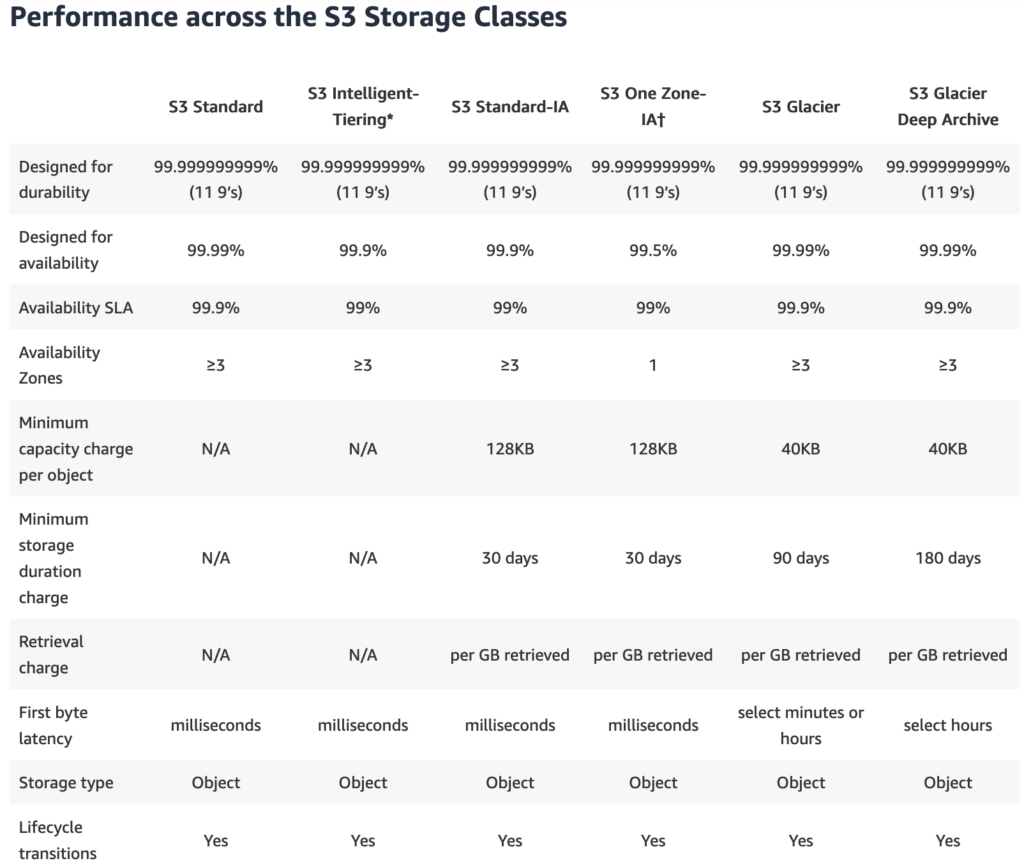
As you may have imagined, each tier comes with a wide variety of performance characteristics. For a more comprehensive visual of the difference between the tiers see the chart below.
In terms of pricing – hold off on that thought. We’re going to visit the pricing of each of these tiers in a later section.
One of the nice things S3 has introduced in recent years is this concept of S3 Object Lifecycles. This feature allows you to transition objects through different transition tiers over time.
For example, you can use Object Lifecycles such that all objects uploaded to your bucket are classified as standard tier. This remains the same for thirty days – after all, most recently uploaded data is most likely to accessed shortly thereafter.
We can then define a rule to move objects into IA of Infrequent Access Tier 31 days after object upload. This will help reduce costs but also guarantee the same levels of performance.
Finally, after 90 days, we decide to archive our data into Glacier or Deep Glacier so that we can retain it for compliance auditing. This allows us to minimize our cost burden for storage on S3 while also being policy compliant.
S3 makes this process extremely easy using Lifecycle Rules. This just involves you following a wizard in the S3 console asking you to define temporal thresholds and when objects should be moved to what tier. I have a tutorial walkthrough on Lifecycle Rules available here.
Up next I want to talk about Security of your S3 objects/buckets.
Security
If you’re into cloud computing news or follow tech focused media outlets, you’ve probably already heard about the security issues with S3. You may have heard about stories such as well known companies leaking customer data. In fact, a quick google search for “S3 Security Breaches” results in some headlines like the following:
“Leaky S3 Bucket at Center of Data Breach”
“Unsecured S3 Bucket found leaking data of 30k customer”
“US Municipalities suffer data breach due to misconfigured S3 Bucket”
I wish there were less headlines like these… but I digress. It turns out the security breaches are in no way due to AWS, but due to customers misconfiguring their bucket and accidentally making it public. Due to the nature of S3 names being globally unique and accessed by name via a URL, bad actors have figured out that if you throw random (or predictable names) into a url with s3.amazonaws.com at the beginning, you run the chance of stumbling on a publiclly accessible S3 bucket.
This is literally how an overwhelming majority of these data leaks occur; a naive engineer setting a bucket to public, and a bad actor randomly throwing darts at a dartboard and hitting a bullseye.
I went off on this tangent to emphasize the importance of understanding the settings of your S3 public, and the implications of making your bucket public.
I may have scared the pants off you, but things aren’t all that bad. In recent years, AWS has added additional friction when attempting to make your bucket or objects public. By default, all created buckets with automatically be private. You can only enable public access by stepping through a ridiculous number of check boxes and confirmation screens before AWS allows it to happen. Afterwards, there is some VERY clear UI elements on the console that indicate your bucket/object is public.
Further, its a two step process to make your content public. First, you need to specifcy on a bucket level that your bucket CAN be public. Then, a second option is required to actually make your bucket/subfodler/object public. Its a two step process meant to prevent you from shooting yourself in the foot.
This is just one element of security, but there are many other lenses you can use to look at Security. Lets explore some other angles…
Data Protection
In terms of data protection, AWS offers 99.99999999999% (thats 11 9’s by the way) of durability. This applies for all storage classes except One Zone IA which is 99.5%.
This essentially means the likelihood of AWS ‘losing’ your data while stored in S3 are slim to none. The odds are so microscopically small its not even worth wasting mental cycles thinking about.
S3 also supports encryption both in transit and at rest. This means you can be sure your data is being securely transmitted and stored on the cloud.
Access
When it comes to access controls, AWS offers a very rich set of option through the Identity and Access Management (IAM) service. Using IAM, you have the ability to specify a granular set of permissions as a policy and apply it to a certain user or role.
IAM is a very powerful permission control system that allows you to lock down access to your bucket’s content.
Separately, you certainly have the option of making your bucket or object public. This would allow global access to your content provided the user has a url or can guess the name of your bucket/object combination.
Auditing
There’s a variety of types of auditing depending on what you’re interested in tracking. S3 offers a variety of auditing options such as:
- Access Logs – Track who and when users are accessing your objects via logs in Amazon Cloudwatch.
- Action Based Logs – Track who is performing actions against your objects via Amazon CloudTrail.
- Alarms – Set alarms on access to your objects that will trigger after a certain number of requests, size limits are hit, etc. via Cloudwatch Alarms.
- Object Lists – Programmatically access content within your S3 buckets using the ListObjects API.
Infrastructure Security
Last but not least is the fact that when using Amazon S3, you’re piggy backing off of one of the most sophisticated networking infrastructures that exists on the planet. The AWS infrastructure as a whole is built for speed of access and countless layers of security.
By using Amazon S3, you’re guaranteed to get reliable, secure, and fast performance.
Its More Than Just Storage…
When thinking of S3, most folks get fixated on the object storage feature of the service. But the truth is, its more than storage, in fact, its A LOT more than just storage. So it turns out that there’s some truly incredible things you can do with S3 by integrating it with other AWS services. So lets run through some example applications that leverage S3 with other AWS services.
Example Application 1 – Data Ingestion Pipeline
Imagine for a second we’re building a real time stock price tracking application meant to consume and analyze price movements in stock Symbols. With this requirement in mind, we can consume data from an input stream and pump it into Amazon Kinesis Data Firehose.
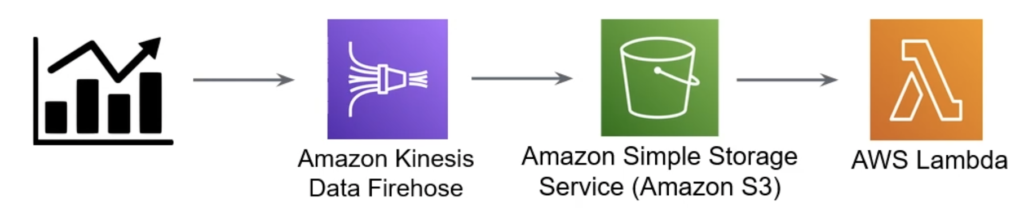
Firehose is a data ingestion and processing service that allows you to ingest large amounts of data and batch it into chunks over time. So for example, we can configure our input stream to chunk our data into 5MB of data batches, and automatically deliver files containing the events to S3.
All of this is done with just a couple clicks in the AWS console and integrating your Kinesis Firehose Stream with S3.
Further, you can combine this feature with a Lambda function invocation such that any time a batch of events are delivered into S3, you can trigger your lambda to pull the data into memory, process its contents, and save it elsewhere.
This is a distributed and serverless data processing pipeline taking advantage of some very popular AWS services.
Example Application 2 – Analytics and Dashboarding
A common use case is to perform analytics or dashboarding on your ingested data. Traditionally, you would have to build data transformation pipelines to ingest and store your data into a database before it can get queried.
Enter Amazon Athena. Amazon Athena is an analytics service that can directly integrate with files stored in S3 and allows you to perform SQL queries on them. This is a really big transformation in the way we access our data.
Behind the scenes, Athena leverages an EMR cluster managed by AWS and queues your jobs submitted to be run against it. You don’t need to load your content from S3 into any database anywhere, as Athena performs its queries on the raw data located in S3.
Athena is a super powerful analytics service that is scalable, cheap (it uses a pay per use model), and reliable method to access your data hosted on S3.
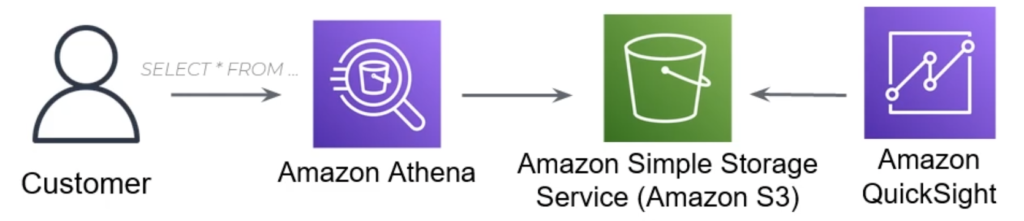
From the dashboarding perspective, we can utilize Amazon Quicksight. Quicksight is an AWS Service that is similar to applications like Tableau; its meant for data exploration and visualization including historgrams, charts, and general representations of data.
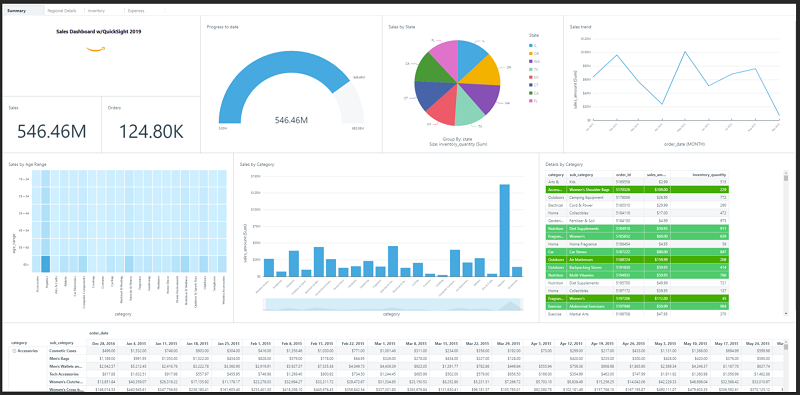
You can integrate your data stored in S3 into quicksight in order to powerful these widgets. This can enable members of your organization to analyze production data with minimal work from the dev team. An example dashboard built in Quicksight can be seen below.
Example 3 – Event Driven Application
In this next example, we talk about a hypothetical event driven application where you can leverage S3 to perform real time image processing with customer notifications.
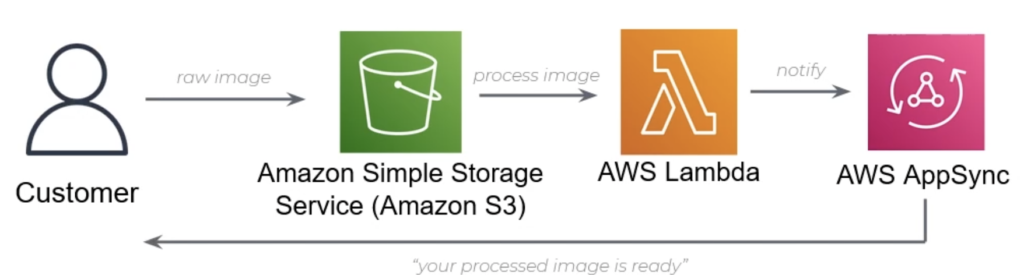
Imagine for a moment we have an application that needs to allow users to upload an image, and you need to process that image before finally notifying the client. You see this pattern all over the internet ranging from PDF Bill Generation, Image Processing, and many many more use cases.
In this example, we leverage that oh so sweet S3 Put Event to trigger our Lambda and process the image. We can subsequently store the processed image back into S3, and notify our client of its availability through our GraphQL subscription endpoint via AWS Appsync. Pretty neat!
Pricing
We finally get to pricing. It turns out that pricing on S3 is variable depending on those storage tiers we discussed earlier. However, the general cost model is explained by three main factors: Storage, Access, and Transfer.
Storage refers to the amount of content we are storing in S3. The more you store, the more you pay – pretty simple. That being said, the cost of storage is considerably attractive feature of S3; the costs are hard to fathom.
For example, with S3 Standard Tier, you can expect to pay .023$ per GB. So if you have 100 GB of data, you would pay a measly $2.30 / month (100Gb * $.0023) just for storage. Really affordable.
In terms of Access, you’re billed by the number of requests you make to S3. This generally falls into two categories: GET and PUT. For S3 Standard, you are charged $.005 per 1000 PUT requests and $.0004 per thousand GET requests.
So if you made 10,000 GET and PUT requests per month, you would be charged a measly $.05 or 5 cents (10 * .005 + 10 * .0004).
Finally, in terms of Data Transfer, you’re charged on the egress of data as it moves out of AWS and into the public internet. This could be drawn down from your dev box, or your on prem applications. $.01 per GB. So $100GB of transfer out from S3 to your dev box would be about whopping $8.91 per month.
You really need to be careful with transfer costs. Its much cheaper if you’re transferring data within AWS regions or using CloudFront as your caching service. Just be aware these prices can quickly stack up.
All in all, this scenario with 100GB of data being stored, 10k PUT and GET requests, 100GB of data transferred from S3 to the public internet, this comes down to $11.26 per month. Keep in mind the significant costs of data transfer, they represent approximately 75% of the total cost here.
Note: a useful tool is S3 Cost Estimator which allows you to input hypothetical scenarios to estimate your monthly costs.
Wrapping Up
S3 has certainly come a long way since its early days in 2006. Since then, new features have been added to protect users, decrease costs, increase performance, and many other benefits. S3 remains as one of AWS most popular services and is used by hundreds of thousands of companies across the world.
I hope you learned a lot from this article. I’d love to hear your thoughts about S3 in the comments section below.


