



If you’re struggling to figure out why your dynamodb scan or query are not returning all of your expected data, this is the article for you.
DynamoDB Scans and Queries have a limitation that only 1MB worth of data can be returned per operation. The number of records returned is dependent on the size of each individual record. Since items in dynamodb are schemaless and can vary amongst eachother, you can very easily run up against the 1MB limit in a Scan or Query.
When your Scan or Query exceeds 1MB worth of data, only a single ‘page’ of items will be returned. Again, the exact quantity depends on how large your items are.
For example, if your records are approximately 1KB each, you would receive up to 1000 records back. If they are 300KB each, you’d only receive three. Keep in mind that each item in your table has a maximum size of 400KB.
If you’re still confused about the difference between DynamoDB Scan and Query, check out this article. But for now, lets dig into some reasons why DynamoDB may not be returning all your results.
How To Determine If Size Limits Are Affecting Your Query Results
To determine if your scan or query is running up against the limit, you need to look at the LastEvaluatedKey that is returned as part of your DynamoDB API call. When performing a scan or query and there is ‘more’ data for you to retrieve, DynamoDB will return a non-null LastEvaluatedKey in your API call.
In your next calls, you need to provide the LastEvaluatedKey as part of your request and DynamoDB will return the next ‘page’ of results. This is called pagination, and its a popular pattern for folks looking to retrieve large numbers of items from their DynamoDB table.
In other words, your scan or query more likely than not is not returning all results because the results being returned exceed the 1MB maximum per call. In order to retrieve the next set, use the LastEvaluatedKey in your next call.
Lets take a look at an example.
LastEvaluatedKey Example
Lets assume we have a starting state table that looks like this:
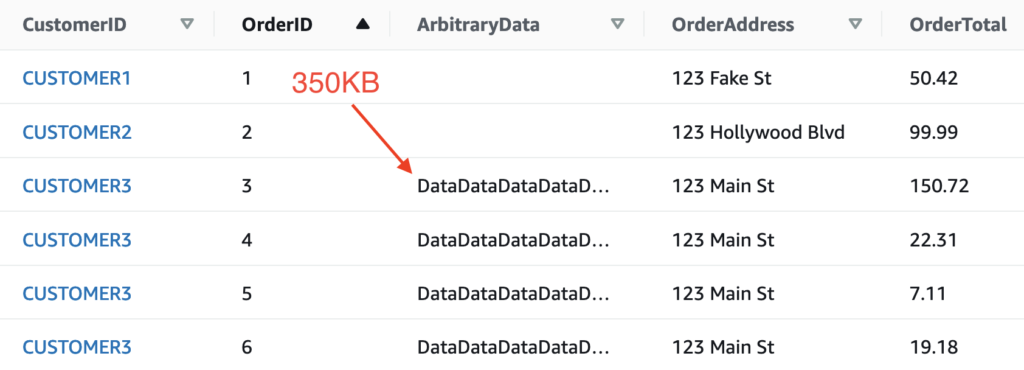
I’ve added a field ArbitraryData that contains approximately 350KB worth of data. The total item size is a tiny bit larger.
Lets take a look at how a DynamoDB Scan operation behaves against this table using the code below.
Request Code:
import boto3
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('CustomerOrders')
response = table.scan()
print(response)This is pretty straightforward code that performs a basic Scan operation against our table. Note that although we’re talking about Scans in this demo, Query works exactly the same way and follows the same rules.
Response:
{
"Records":[
"... 4 items ... "
],
"Count":4,
"ScannedCount":4,
"LastEvaluatedKey":{
"CustomerID":"CUSTOMER3",
"OrderID":"5"
},
"ResponseMetadata":[
"..."
],
"RetryAttempts":0
}Note that I’ve truncated the response a bit to focus on whats important here.
First of all, notice that our Count field is equal to 4; however, our DynamoDB table contains 6 items as seen in the starting state. This means we only retrieved 4 of 6 items in this one scan operation.
Also notice our LastEvaluatedKey field – it contains a non-null value. This is the indicator that we’re running up against that 1MB limit as part of our scan. Interistingly, the value for LastEvaluatedKey is a piece of our data record. We don’t really need to care about why this value is what it is, its just an interesting observation.
You may enjoy this article on DynamoDB Scan VS Query – When to Use What?
Now that we can see we’re running up against the limits, we can perform pagination using the python in the next section retrieve all of our results.
Using Pagination To Retrieve All Your Data
To retrieve all of our data, we make a couple changes to our original code:
import boto3
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('CustomerOrders')
lastEvaluatedKey = None
items = [] # Result Array
while True:
if lastEvaluatedKey == None:
response = table.scan() # This only runs the first time - provide no ExclusiveStartKey initially
else:
response = table.scan(
ExclusiveStartKey=lastEvaluatedKey # In subsequent calls, provide the ExclusiveStartKey
)
items.extend(response['Items']) # Appending to our resultset list
# Set our lastEvlauatedKey to the value for next operation,
# else, there's no more results and we can exit
if 'LastEvaluatedKey' in response:
lastEvaluatedKey = response['LastEvaluatedKey']
else:
break
print(len(items)) # Return Value: 6Woo! We’re finally getting all our results. Lets dissect the code a little bit.
Notice in the while loop for our first operation we do not provide the ExclusiveStartKey as part of our request. Pyton is finnicky in this sense such that if you provide this key with a null value, it will throw an exception. So we worked around that by having a simple if/else.
In subsequent calls, we use the extracted LastEvaluatedKey from the result set as the input for the ExclusiveStartKey. When this value is null (either after our first operation or any subsequent operation), our final if/else block will exit.
So thats it! This is why DynamoDB isn’t returning all of your data, and this is how to fix it. Keep in mind this concept applies for any language you’re using – its not just a python thing.
You may also enjoy these other articles:




Unfortunately, this code doesn’t work. You get an error as you are not allowed to set the ExclusiveStartKey to None. If a software at Amazon is having trouble what hope do the rest of us have?
Daniel – can you suggest a fix?
Hi Beth,
I just tested the code on my machine and it seems to be working fine – I am paginating and getting all the results back. Perhaps this is an issue with your setup? Can you post the code you are using and what your Table schema is and perhaps I can help?
Daniel
Hi Daniel,
in my case I know the scan will bring me only one element back but I still get the ‘LastEvaluatedKey’. Lets say maybe there are more, I call the scan again with ExclusiveStartKey= response[‘LastEvaluatedKey’] and the response gives me “Items”:[] and still I see
“LastEvaluatedKey”: {
“PK”: “E#23411”,
“SK”: “ER34523#1992-11-16 00:00:00.0#R”
},
What is the logic to stop?
while ‘LastEvaluatedKey’ in response: — will run forever
Thanks,
Vera
part 2
I mean except the obvious to check the Items size. But that is not the point, is it? ‘LastEvaluetedKey’ should not be there. But it is! This is my code (just to check the LastEvaluetedKey) and will run forever!
response = table.scan(
FilterExpression= Attr(‘PK’).eq(‘something’)
)
while ‘LastEvaluatedKey’ in response:
response = table.scan(
FilterExpression= Attr(‘PK’).eq(‘something’),
ExclusiveStartKey= response[‘LastEvaluatedKey’]
)
return response