




In my previous post, I spoke at length covering approximately 20 of the new major service and feature announcements from AWS re:invent this year. Most of these came from the Andy Jassy Keynote, but as the week has gone on, more product and feature enhancements have been announced.
In this blog post, I’m going to walk you through some of the other major service announcements from aws reinvent 2020.
#1 – Lambda Launches Container Support
Those of you familiar with Lambda probably love it because you don’t have to worry about managing your own servers. This alleviates much of the headaches of maintenance, security upgrades, patching, and many more pain points.
In this years reinvent, AWS announced support for containers. This means customers will be able to package container images up to 10gb and deploy them to be run on the Lambda engine. Users can specify their exact environment specifications and dependencies using familiar tools like docker, and deploy all that right into Lambda to spin up and manage.
This is a huge win for those of you closely tied to the Docker ecosystem and were looking for a way to easily launch docker based containers without having to worry about machines or maintenance. Your prayers are answered with Lambda container support. Read more about it here.
#2 – Lambda Insights General Availability
Earlier this year in October, AWS announced a fantastic new operational/monitoring tool called Lambda Insights.
Lambda insights helps answer the question ‘how are my lambdas performing?’. Previously, users had to pore over Lambda metrics or build custom dashboards in order to get insight into their Lambda based application’s performance. With this new tool, customers can simply enable Lambda Insights on their lambda function, and watch as Lambda does all the heavy lifting to collect, summarize, and present the critical metrics.
You may be asking yourself, what does this feature do that I can’t already do with a creative dashboard? Well the answer seems to be: quite a bit. Although I haven’t personally used it yet, it looks like this feature is capable of collecting information that isn’t typically available in the standard Lambda metric suite. This includes things like graphing the cases of your most expensive functions, what their memory profile looks like, and more.

For more details, read on here.
#3 – S3 Strong Read after Write Consistency
S3 was originally launched back in 2006 by AWS. It was one of the first services and remains most one of the most popular offering.
In this year’s reinvent, AWS announced a feature enhancement called S3 Strong Consistency. Understanding what this means requires a small examination into what was there before it.
Prior to this update, S3 used a model called Eventual Consistency. This means that when a file was written to S3, its contents would be replicated to a multitude of ‘replica’ nodes that would contain copies of the file you just uploaded. This happens in an asynchronous mode, meaning that if a PutObject/UpdateObject action takes place, there is a small (usually negligible delay) between when you get back a 200 OK, and when that data is propagated to the remainder of the S3 storage nodes.
At first glance, this doesn’t seem like much of a problem. But this model means that it you upload data to s3, it is possible that a subsequent read shortly after hit one of the replica nodes that do not have the updated data yet. This means stale data. For many mission critical applications, this type of behaviour is unacceptable.
With this new update, AWS announced that all put/update/list operations would behave in a strongly consistent way. This means that your operation will not return until all data is propogated to the replicana nodes. Effectively, what you write is what you read.
Bravo S3 team!
#4 – S3 Multi Destination Replication
S3 replication allows users to copy their objects from one S3 bucket to different regions or using cross region replication (crr), or alternatively to different buckets.
Prior to this update, if a developer wanted to copy data from one S3 bucket for more than 1 destination, they had to ‘roll their own’ solution. Very time consuming and costly.
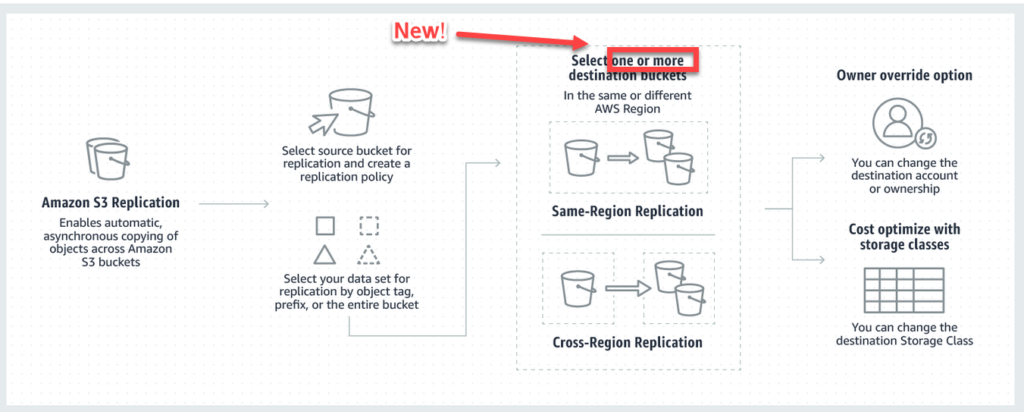
With this new update, AWS now natively supports multi destination content replication. This means that developers no longer have to worry about the mechanics and infrastructure of copying S3 data to multipel locations, and can instead rely on automated aws processes to handle the complexity. Win win!
#5 – Serverless Batch Jobs with Fargate
AWS Batch was announced in 2016 to help developers run high throughput batch computing jobs on the cloud.
Prior to this update, users had to use on demand or spot ec2 instances to run their workloads. This resulted in costly bills and the need to monitor and manage these instances throughout the workload’s execution.
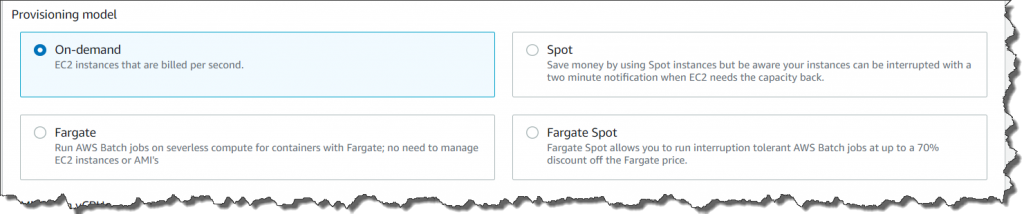
With this new announcement, users can now take advantage of serverless infrastructure to run their batch jobs using AWS Fargate. With this new mode, users just need to select the fargate launch option and AWS will take care of finding, provisioning, launching, and maintaining all the necessary infrastructure to run your jobs.
Make my life easier? Yes please! More reading here.
#6 – Public ECS Registry
Those of you familiar with Docker probably know about Dockerhub – the public repository used to store and manage container based images for your application.
With this launch, AWS announced a public ECS repository developers can upload their images onto to share their images with friends, coworkers, or even the general public.
All AWS customers get 50gb of free storage per month. Anonymous users can access 500gb of image content per month. If you need more, you can simply register with AWS and up that limit to 5TB. Learn more about the ECS Registry here.
#7 – Computer Vision at the Edge with AWS Panorama
Computer vision is being increasingly adopted around the world for a myriad of use cases. Whether it be measuring efficiency, ensuring security, or analyzing trends, computer vision has many applications in a diverse set of domains.
With AWS Panorama, AWS is looking to make a move into computer vision edge based computing. Panorama is a physical device that can be integrated with on premises devices (video feeds, etc) to perform spot analysis.
The device can turn existing cameras into smart cameras for things like image detection or pattern recognition. Learn more about it here.



